Verlust und Perplexity überwachen: Signale während des LLM-Trainings lesen

Wenn du ein Large Language Model (LLM) trainierst, siehst du täglich hunderte von Zahlenflüssen auf deinem Bildschirm. Verlustwerte, Perplexity-Scores, Genauigkeitskurven - aber was bedeutet das wirklich? Viele Entwickler sehen nur, dass der Verlust sinkt, und denken: Alles gut. Doch das ist wie ein Automechaniker, der nur auf die Motorwarnlampe schaut, ohne den Motor zu hören. Der Verlust und die Perplexity sind keine bloßen Zahlen. Sie sind die Stimmen deines Modells - und wenn du lernst, sie zu lesen, erkennst du Probleme, bevor sie dich ins Verderben stürzen.
Was ist Perplexity, und warum ist sie so wichtig?
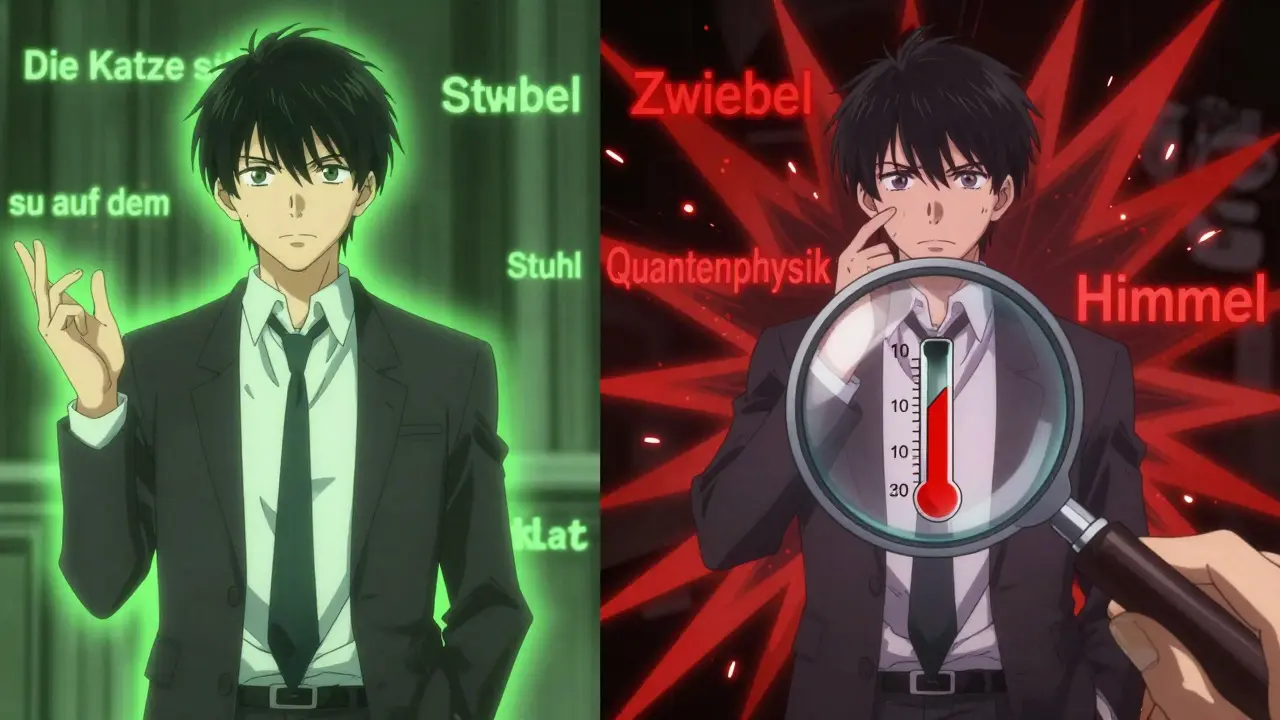
Perplexity misst, wie überrascht dein Modell ist, wenn es einen neuen Text sieht. Stell dir vor, du gibst dem Modell einen Satz wie „Die Katze sitzt auf dem“ - und es soll das nächste Wort vorhersagen. Wenn es mit hoher Sicherheit „Stuhl“ sagt, ist die Perplexity niedrig. Wenn es zwischen „Stuhl“, „Himmel“, „Zwiebel“ und „Quantenphysik“ zögert, ist die Perplexity hoch. Mathematisch ist sie einfach: e hoch Verlust. Wenn dein Cross-Entropy-Verlust 3,0 beträgt, ist die Perplexity etwa 20,1. Das bedeutet: Das Modell verhält sich, als hätte es bei jedem Wort etwa 20 gleich wahrscheinliche Optionen zur Auswahl - und es wählt die richtige mit guter Wahrscheinlichkeit.
Das ist der Grund, warum Perplexity so stark in der Forschung genutzt wird. GPT-3 hatte eine Perplexity von etwa 22 auf dem Penn Treebank-Datensatz - GPT-2 lag bei 45. Der Abfall war nicht nur ein Zahlenwert. Er zeigte: Das Modell verstand Sprache tiefer. Es erkannte Muster, Kontexte, Grammatik - nicht nur Wörter. Und das ist der Kern: Perplexity misst nicht, ob das Modell eine Frage richtig beantwortet. Es misst, ob es die Sprache grundsätzlich versteht.
Verlust vs. Perplexity: Was misst was?
Der Cross-Entropy-Verlust ist die direkte Optimierungsgröße. Dein Optimierer - AdamW, SGD, oder ein anderer - versucht, diesen Wert zu minimieren. Er arbeitet in Nats (natürliche Logarithmen) oder manchmal in Bits. Aber Nats sind abstrakt. Ein Verlust von 2,7 sagt dir nicht, ob das Modell gut ist. Ein Perplexity-Wert von 25 hingegen? Den kannst du dir vorstellen. 25 bedeutet: Bei jedem Wort hat das Modell so viel Unsicherheit, als würde es aus einem Wörterbuch mit 25 möglichen Wörtern wählen. Ein Modell mit Perplexity 100? Das ist wie ein Kind, das Wörter raten muss, ohne zu wissen, was sie bedeuten.
Und hier ist der entscheidende Punkt: Perplexity ist nicht unabhängig vom Verlust. Sie ist seine übersetzte Version. Wenn der Verlust sinkt, sinkt die Perplexity. Wenn sie steigt, ist etwas schiefgelaufen. Aber du solltest beide überwachen. Der Verlust zeigt dir die mathematische Richtung. Die Perplexity sagt dir, was das bedeutet - in menschlichen Begriffen.
Wie du Perplexity richtig misst - und was du falsch machen kannst
Ein häufiger Fehler: Du berechnest Perplexity über ganze Sätze - und vergisst, sie auf das Wort zu normalisieren. Das führt zu verzerrten Werten. Ein langer Text hat mehr Wörter - und damit mehr Gelegenheiten, Fehler zu machen. Die richtige Methode: Berechne die Perplexity pro Token. Jeder Token zählt gleich - egal ob er ein Wort, ein Komma oder ein Sonderzeichen ist. Hugging Face’s Transformers-Bibliothek macht das automatisch, wenn du model.evaluate() verwendest. Aber wenn du es selbst implementierst - achte darauf, dass du den Durchschnitt der negativen Log-Likelihoods nimmst, dann e hochrechnest.
Ein weiterer Fehler: Du vergleichst Perplexity-Werte zwischen verschiedenen Datensätzen. Ein Modell mit Perplexity 20 auf Penn Treebank hat eine völlig andere Sprachfähigkeit als eines mit Perplexity 20 auf Webtext. Penn Treebank ist sauber, grammatisch korrekt. Webtext ist voller Slang, Rechtschreibfehler, Emojis. Ein Modell, das auf Webtext trainiert ist, hat natürlicherweise eine höhere Perplexity - nicht weil es schlechter ist, sondern weil die Sprache unordentlicher ist. Vergleiche nur innerhalb desselben Datensatzes.
Und vergiss nicht: Die Berechnung ist rechenintensiv. Aber nicht so sehr wie das Training. In der Praxis kostet die Überwachung der Perplexity nur 1-2 % zusätzliche Rechenzeit. Du kannst sie alle 500 Trainings-Schritte berechnen - das ist der Goldstandard. Zu oft? Du verlangsamt das Training unnötig. Zu selten? Du verpasst Warnsignale.
Was ein Plateau oder Anstieg der Perplexity wirklich bedeutet
Wenn die Perplexity stabil sinkt - perfekt. Du bist auf dem richtigen Weg. Aber was, wenn sie nach 80 % des Trainings auf 25,3 stecken bleibt? Viele denken: Das Modell ist fertig. Aber das ist oft falsch. Ein Reddit-Nutzer berichtete, dass sein Modell bei 25,3 stagnierte - aber die Genauigkeit auf einer Aufgaben-Testmenge stieg weiter. Die Lösung? Er änderte den Lernratenplan. Die Perplexity war ein Indikator, nicht ein Endziel.
Ein Anstieg der Perplexity ist ein rotes Licht. Das kann bedeuten:
- Du hast Overfitting: Das Modell hat die Trainingsdaten auswendig gelernt - es kann nicht mehr auf neue Daten generalisieren.
- Du hast Datenleckage: Ein Teil der Validierungsdaten ist versehentlich in den Trainingsdatensatz geraten. Das ist ein häufiger Fehler - und die Perplexity auf der Validierungsseite ist plötzlich niedriger als auf der Trainingsseite. Das ist ein klarer Hinweis.
- Die Lernrate ist zu hoch: Das Modell springt zwischen Lösungen hin und her, statt sich zu stabilisieren.
- Der Datensatz ist schlecht: Zu viele Rauschdaten, zu viele Wiederholungen, zu viele unvollständige Sätze.
Ein Beispiel aus der Praxis: Ein Entwickler bemerkte, dass seine Validierungs-Perplexity 15 % niedriger war als die Trainings-Perplexity. Er dachte, sein Modell sei überdurchschnittlich gut. Aber als er die Daten prüfte, fand er heraus: 12 % der Validierungsdaten waren identisch mit Trainingsdaten - ein Copy-Paste-Fehler. Die Perplexity hatte ihn gewarnt - er hatte nur nicht richtig zugehört.

Warum Perplexity nicht alles ist - und was du zusätzlich brauchst
Perplexity ist ein hervorragender Diagnose-Tool - aber kein Endziel. Ein Modell kann eine Perplexity von 18 haben und trotzdem vollkommen nutzlos sein. Warum? Weil es grammatisch perfekt ist - aber sinnlos. Ein Beispiel: „Der Mond ist ein Käse, der von Ratten bewacht wird.“ Das ist ein Satz, den ein gut trainiertes Modell mit niedriger Perplexity erzeugen könnte - weil es die Wörter gut kombiniert. Aber der Inhalt ist absurd.
Das ist der große Knackpunkt: Perplexity misst Sprachmuster - nicht Wahrheit, Logik oder Relevanz. Deshalb ist sie in der Forschung dominant - aber in der Industrie nicht ausreichend. 92 % der LLM-Papers 2024 verwendeten Perplexity als Hauptmetrik. Aber nur 63 % der Produktionsysteme nutzen sie allein. Unternehmen wie AWS SageMaker oder Google kombinieren sie mit ROUGE (für Textzusammenfassung), BLEU (für Übersetzung) oder sogar mit „Ask-LLM“-Bewertungen - wo ein anderes Modell die Antwort auf eine Frage bewertet.
Ein arXiv-Paper aus Februar 2024 zeigte: Perplexity-Filterung, die schlechte Daten rausschmeißt, wählt oft Texte aus, die grammatikalisch perfekt sind - aber semantisch flach. Die „Ask-LLM“-Methode erkannte dagegen schnell, welche Texte wirklich nützlich waren. Das ist die Zukunft: Perplexity als erster Filter, dann tiefere Prüfungen.
Was kommt als Nächstes - und wie du dich darauf vorbereitest
Die Industrie bewegt sich weg von der alleinigen Abhängigkeit von Perplexity. Meta arbeitet an „Contextual Perplexity“, einem neuen Metrikansatz, der nicht nur Wortfolgen, sondern auch semantische Kohärenz misst. Google hat „Perplexity Explorer“ veröffentlicht - ein Tool, das die Perplexity-Entwicklung visuell darstellt, Token für Token. AWS SageMaker hat „adaptive Perplexity Monitoring“ eingeführt: Das System passt die Überwachungshäufigkeit automatisch an - wenn die Perplexity stabil ist, wird seltener evaluiert. Wenn sie schwankt, wird intensiver geprüft.
Und es gibt bereits Prototypen, die Perplexity ohne vollständige Inferenz schätzen - durch Simulationen. Das könnte die Evaluationskosten um 85 % senken. Das ist kein Science-Fiction - das ist der nächste Schritt.
Du musst nicht alles sofort nutzen. Aber du solltest wissen: Perplexity wird nicht verschwinden. Sie bleibt der grundlegende Signalgeber - weil sie direkt mit dem Lernziel verbunden ist. Dein Modell lernt, Wörter vorherzusagen. Perplexity misst, wie gut es das tut. Alles andere ist eine zusätzliche Prüfung.
Also: Überwache sie. Verstehe sie. Vertraue ihr - aber nicht blind. Sie ist dein Kompass, nicht deine Landkarte. Und wenn du lernst, ihre Signale zu deuten, wirst du nicht nur bessere Modelle trainieren - du wirst auch schneller erkennen, wann du aufhören musst, und wann du weitergehen sollst.
Maximilian Erdmann
Dezember 17, 2025 AT 13:40Perplexity ist ja cool und alles, aber ich hab mal ein Modell getrainiert, das 12 als Wert hatte… und dann hat’s ‘nem User ‘ne Anleitung gegeben, wie man ‘ne Waschmaschine mit Backpulver repariert. 😅
Rolf Jahn
Dezember 17, 2025 AT 20:01Oh wow, endlich jemand, der nicht nur ‘Loss sinkt = alles gut’ schreit. Ich dachte, ich bin der Einzige, der das nervt. 🙄
Günter Rammel
Dezember 19, 2025 AT 18:04Der Punkt mit den Datenlecks ist goldwert. Ich hab vor 3 Monaten ein Modell 2 Wochen lang trainiert, nur weil ich versehentlich die Testdaten in den Trainingsset gezogen hatte. Die Perplexity war niedriger als bei GPT-4 – bis ich die Daten geprüft hab. Dann war’s wie ‘ach, du lieber Himmel’. 😅
Perplexity ist der erste Alarm, aber nie das letzte Wort. Immer mit Metrics und menschlicher Evaluierung kombinieren.
Kristian Risteski
Dezember 19, 2025 AT 20:27Ich find’s immer wieder faszinierend, wie so ein Modell ‘ne Sprache lernt – ohne zu verstehen, was ‘Käse’ oder ‘Quantenphysik’ bedeutet. Es ist wie ein Kind, das alle Wörter auswendig kann, aber nicht weiß, was ‘Liebe’ ist. 🤔
Helga Goldschmidt
Dezember 20, 2025 AT 04:31Perplexity pro Token ist wirklich der einzige saubere Weg. Ich hab mal versehentlich über Sätze gemittelt – Ergebnis: total verfälscht. Danke für die klare Erklärung.
Francine Ott
Dezember 20, 2025 AT 21:43Es ist bemerkenswert, wie sehr wir uns an numerischen Metriken klammern, obwohl wir wissen, dass Sprache nicht reduzierbar ist. Perplexity misst Vorhersagbarkeit – nicht Bedeutung. Ein Modell kann perfekt grammatikalisch sein und gleichzeitig vollkommen leer. Das ist nicht nur ein technisches, sondern ein philosophisches Problem. Wir optimieren für Oberflächen, nicht für Tiefe.
Wenn wir wirklich verstehen wollen, was Sprache ist, müssen wir über Metriken hinausgehen – in Richtung kognitiver Plausibilität, kontextueller Kohärenz, emotionaler Resonanz. Aber das ist schwer zu messen. Deshalb bleiben wir bei Perplexity. Tragisch, aber verständlich.
Ich frage mich: Wann werden wir akzeptieren, dass ein Modell, das keine Empathie hat, niemals echte Kommunikation erzeugen kann – egal wie niedrig seine Perplexity ist?
Vielleicht ist die wahre Perplexity nicht die des Modells, sondern die unseres eigenen Verlangens, es als intelligent zu sehen.
Ich danke Ihnen für diese klare, nüchternen Betrachtung. Sie erinnert daran, dass Technik nur ein Spiegel ist – und wir selbst entscheiden, was wir darin sehen.
Koray Döver
Dezember 21, 2025 AT 16:54Ich hab das mit dem Datenleck auch schon erlebt – und dann nochmal bei einem Kollegen. Der hat die Validierungsdatei einfach mit der Trainingsdatei überschrieben. Hat 3 Wochen gebraucht, das zu merken. 🤦♂️
Und jetzt kommt der Clou: Er hat das Modell als ‘State-of-the-Art’ in einer Präsentation vorgestellt. Die Leute haben applaudiert. Ich hab nur gefragt: ‘Und wie sieht’s mit den Originaldaten aus?’ – Schweigen. Dann hat er mich rausgeworfen. 😅
Thomas Lüdtke
Dezember 22, 2025 AT 09:25Perplexity 100 = Kind, das Wörter rät. Ja, genau. Meine Oma hat auch so geredet, wenn sie den Fernseher nicht verstand. 😂
Nadja Blümel
Dezember 23, 2025 AT 00:15Ich find’s interessant, dass Perplexity so oft als Maßstab genommen wird – obwohl es so wenig mit echter Nützlichkeit zu tun hat. Aber ich sag nichts. Ich beobachte nur.
Arno Raath
Dezember 23, 2025 AT 08:33Perplexity ist wie die Musik, die ein Künstler hört, während er malt – sie sagt dir, ob es ‘richtig’ klingt, aber nicht, ob es ein Meisterwerk ist. Ich hab ein Modell, das Perplexity 17 hat – und es erzeugt Gedichte, die mich zum Weinen bringen. Und andere, die 22 haben und nur ‘Hallo, wie geht’s?’ wiederholen. 🤷♂️
Also: Zahlen sind schön. Aber wer die Seele des Modells hören will, muss tiefer gehen. Und wer das nicht tut… na ja, der hat wahrscheinlich auch nie einen echten Künstler verstanden.