KPIs und Dashboards zur Überwachung der Gesundheit von Large Language Models
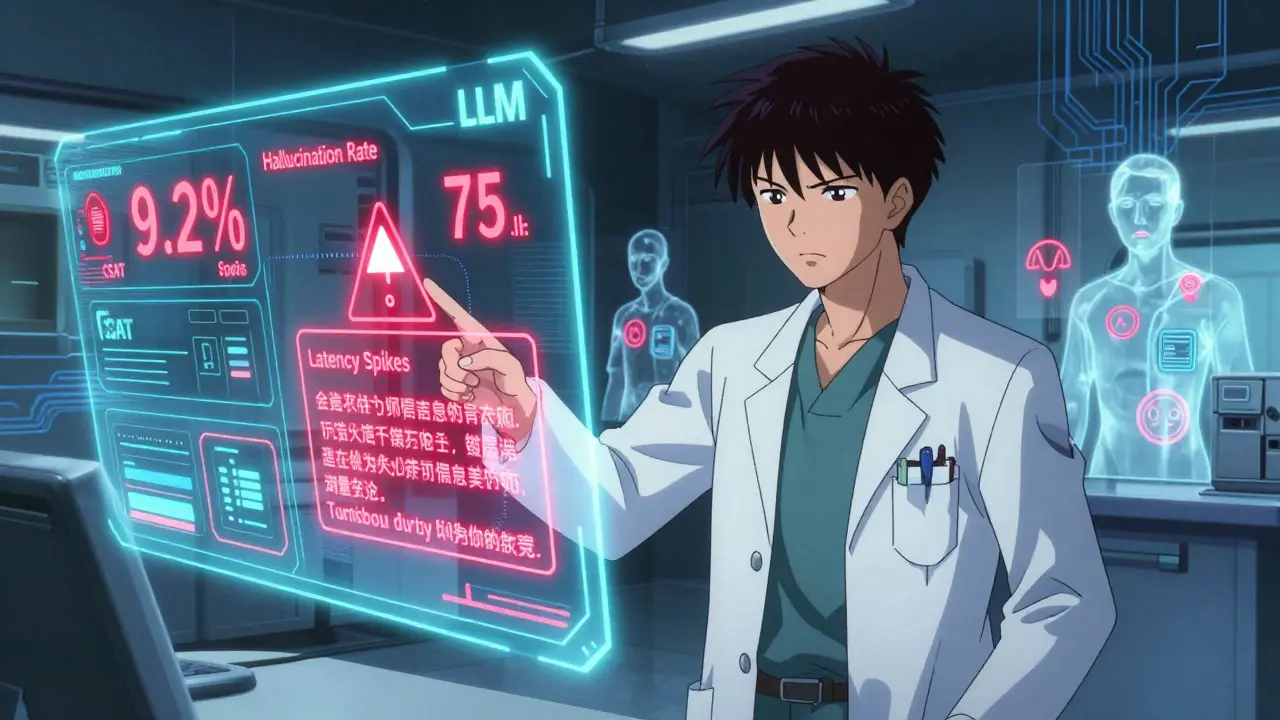
Stellen Sie sich vor, Ihr Large Language Model (LLM) gibt medizinische Diagnosen ab - und irrt sich jedes zehnte Mal. Oder es verlangsamt sich so sehr, dass Kunden aufgeben, bevor sie eine Antwort erhalten. Oder es generiert Inhalte, die rechtliche Risiken mit sich bringen. Diese Szenarien sind keine Fiktion. Sie passieren täglich in Unternehmen, die KI ohne klare Überwachung einsetzen. Die Lösung? LLM Überwachung durch gezielte KPIs und intelligente Dashboards.
Warum reichen herkömmliche KI-Monitoring-Methoden nicht mehr?
Früher haben Unternehmen Machine Learning-Modelle über Genauigkeit und Rechenzeit überwacht. Das funktioniert bei Klassifizierern, die zwischen Katzen und Hunden unterscheiden. Aber ein LLM, das einen medizinischen Bericht schreibt oder einen Kundenberater simuliert, erzeugt offene, kreative Antworten. Es kann Dinge erfinden - sogenannte Halluzinationen. Es kann sich widersprechen. Es kann in 10 Sekunden 128.000 Token verarbeiten - und dabei 82 % der Rechenzeit nur für die Modellinferenz verwenden, wie eine Enterprise-Nutzerin bei Coralogix dokumentierte. Traditionelle Tools sehen das nicht. Sie messen nur, ob der Server läuft. Nicht, ob die Antwort richtig ist.Die vier Säulen der LLM-Gesundheit
Effektive Überwachung basiert auf vier Kernbereichen, wie sie Google Cloud und AWS beschreiben. Jeder Bereich hat spezifische Messgrößen.- Modellqualität: Wie gut ist die Antwort? Hier zählen Halluzinationsrate (Prozent der falschen Fakten), Kohärenz (Bewertung durch Menschen auf Skala 1-5), Flüssigkeit (Grammatikfehler pro 100 Wörter), Sicherheit (Anteil unangemessener Inhalte) und Fundiertheit (Prozent der Aussagen, die nur auf bereitgestelltem Kontext basieren).
- Operationelle Effizienz: Wie schnell und stabil läuft das System? Wichtige KPIs: Anfragen pro Sekunde, Token pro Minute, Latenz (Zeit vom Start bis zum ersten Antwort-Token), Auslastung von GPU/TPU und Anzahl der Serverknoten.
- Nutzerbeteiligung: Nutzen die Menschen das System? Messbar an Kundenzufriedenheit (CSAT), Abbruchraten, Antwortzeit vs. Abschlussrate. Eine Studie von Codiste zeigte: Eine 10 %ige Reduktion der Halluzinationen führte zu einem 7,2 %igen Anstieg der Kundenzufriedenheit.
- Kostenmanagement: Wie teuer ist jede Antwort? KPIs: Kosten pro 1.000 Token, monatliche Gesamtausgaben. AWS stellt fest: Unternehmen, die 30-40 % der Kosten einsparen, messen diese Werte mit einer Genauigkeit von fünf Minuten.
Branchenspezifische KPIs: Was unterscheidet Medizin von Finanzen?
Ein LLM in der Krankenversicherung hat andere Risiken als eines im E-Commerce.In der Medizin geht es um Leben und Tod. Hier sind KPIs wie diagnostische Genauigkeit (verglichen mit Goldstandard-Diagnosen), Korrelation mit Patientenergebnissen und Bias-Erkennung nach Alter, Geschlecht oder Ethnie entscheidend. Censinet berichtet, dass HIPAA-konforme Systeme 22 % mehr Datenvalidierungen einbauen als allgemeine Lösungen. Ein Krankenhaus in Oregon reduzierte durch Echtzeit-Monitoring die Zeit bis zur Behebung von HIPAA-Verstößen von 72 auf nur 2 Stunden - 87 % der Probleme wurden vor der Eskalation gefixt.
In der Finanzbranche steht Compliance im Vordergrund. Hier zählen: Vollständigkeit der Audit-Trails, Regulierungs-Konformitäts-Scores und Erklärbarkeit - also: Kann man nachvollziehen, warum das Modell eine Kreditablehnung empfahl? MIT Sloan dokumentierte, wie ein Algorithmus in Schweden das Risiko eines plötzlichen Herztods vorhersagt - und dieser Vorhersagewert selbst wurde zur KPI für die kardiologische Abteilung.

Wie bauen Sie ein funktionierendes Dashboard auf?
Ein Dashboard ist kein Sammelsurium von Grafiken. Es ist eine Entscheidungsplattform.Beginnen Sie mit der Definition von Business-Zielen. Nicht: „Wir brauchen hohe Genauigkeit.“ Sondern: „Wir wollen, dass 90 % der Kunden nach einer Beratung den Vertrag abschließen.“ Dann arbeiten Sie rückwärts: Welche LLM-KPIs beeinflussen diese Zahl? Ist es die Antwortgeschwindigkeit? Die Klarheit der Sprache? Die Vermeidung von falschen Angeboten?
Verwenden Sie Tools wie Grafana oder Google Clouds Vertex AI Monitoring. Verknüpfen Sie die KPIs mit Logs und Traces - so erkennen Sie, ob eine Latenzspitze mit einem neuen Modell-Update zusammenhängt. Setzen Sie klare Alarmgrenzen: Ein Anstieg der Halluzinationsrate um 15 % sollte nicht nur gemeldet, sondern sofort als „hochpriorisiert“ markiert werden, wenn es um medizinische oder rechtliche Inhalte geht. AWS betont: Dokumentieren Sie jedes Threshold mit dem erwarteten Risiko - „20 % mehr Halluzinationen = 300.000 $ Strafe nach GDPR“.
Die häufigsten Fehler bei der Implementierung
Viele Unternehmen scheitern nicht an der Technik, sondern an der Herangehensweise.- Keine Ground Truth: Wie wissen Sie, ob eine Antwort richtig ist? Ohne menschliche Evaluatoren (mindestens 3-5 pro 100 Beispiele) sind Messwerte wertlos. Botscrew empfiehlt für Unternehmen 100-500 Testfälle - in regulierten Branchen mindestens 500.
- Alert Fatigue: 57 % der Praktiker berichten von zu vielen unnötigen Warnungen. Lösung: Feinabstimmung der Schwellenwerte je Abteilung. Ein Support-Team braucht andere Alarme als das Compliance-Team.
- Ignorieren der Kosten: Monitoring erhöht die Infrastrukturkosten um 12-18 %. XenonStack bestätigt das. Aber wenn Sie nicht messen, zahlen Sie noch mehr - durch verlorene Kunden, rechtliche Strafen oder ineffiziente Modelle.
- Keine Verknüpfung mit Geschäftsdaten: Das größte Missverständnis: Nur Technik messen. Gartner prognostiziert: Bis 2025 werden 65 % der Unternehmen KPIs mit direktem Geschäftsbezug nutzen - im Jahr 2023 waren es nur 28 %.

Was kommt als Nächstes? Die Zukunft der LLM-Überwachung
Die Technik entwickelt sich rasant. Google Cloud hat im Oktober 2024 eine Funktion hinzugefügt, die vorhersagt, wie sich eine 10 %-ige Verbesserung der Halluzinationsrate auf die Kundenzufriedenheit auswirkt - also: Business Impact Forecasting. Coralogix integriert jetzt KI-Überwachung direkt in klinische Entscheidungssysteme: Wenn ein LLM eine Diagnose vorschlägt, die mehr als 5 % von medizinischen Leitlinien abweicht, wird automatisch ein Arzt alarmiert.Die nächste Stufe: causale KI. Anstatt nur zu erkennen, dass etwas schiefgelaufen ist, sagt das System: „Die Latenz stieg, weil das Modell am 12. Dezember aktualisiert wurde und der neue Prompt-Template die Anfrage auf 3x mehr Token erweitert hat.“ Diese Technik ist noch in Beta, aber bei 12 Krankenhäusern prognostiziert sie Halluzinationsanstiege mit 73 % Genauigkeit 24-48 Stunden im Voraus. Gartner sagt: Bis 2026 wird 80 % der LLM-Überwachung solche Ursachenanalysen enthalten - und die mittlere Behebungszeit um 65 % reduzieren.
Wie fangen Sie an? Ein Praxisplan
Sie brauchen kein Team von 20 Data Scientists. Fangen Sie klein an.- Wählen Sie einen Pilot-Prozess: Nehmen Sie eine Anwendung, die schon läuft - z. B. einen Chatbot für Kundenfragen.
- Definieren Sie 3 KPIs: Halluzinationsrate, Latenz, CSAT. Nicht mehr.
- Setzen Sie eine einfache Visualisierung auf: Nutzen Sie Grafana mit Prometheus. Zeigen Sie die drei Werte in Echtzeit.
- Legen Sie eine Alarmgrenze fest: „Wenn Halluzinationen über 8 % steigen, sende eine E-Mail an den Teamleiter.“
- Werten Sie alle 2 Wochen aus: Was hat sich verändert? Hat sich die Kundenzufriedenheit verbessert? Was hat der Algorithmus falsch gemacht?
Startups schaffen das in 2-4 Wochen. Große Unternehmen brauchen 8-12 Wochen - wegen Integrationsaufwand. Aber der erste Schritt ist immer derselbe: Messen, was wirklich zählt - nicht was leicht zu messen ist.
Frequently Asked Questions
Was ist eine Halluzination bei einem Large Language Model?
Eine Halluzination ist eine Antwort, die Fakten enthält, die nicht in den bereitgestellten Daten oder im Kontext stehen. Das Modell erfindet Informationen - z. B. einen nicht existierenden Medikamentenwirkstoff oder eine falsche Rechtsvorschrift. Diese Fehler sind besonders gefährlich in Bereichen wie Medizin, Recht oder Finanzen. Die Halluzinationsrate wird als Prozentsatz der Antworten gemessen, die mindestens eine falsche Aussage enthalten.
Wie viel kostet die Überwachung eines LLM?
Die Kosten für Monitoring steigen um 12-18 % gegenüber dem reinen Betrieb des Modells, wie XenonStack bestätigt. Das liegt an zusätzlicher Rechenleistung für Evaluierungen, Speicherung von Logs und Echtzeit-Analysen. Ein großes Unternehmen gibt durchschnittlich 185.000 US-Dollar pro Jahr für Monitoring-Infrastruktur aus. Aber das ist oft günstiger als ein einziger Skandal - etwa durch falsche medizinische Empfehlungen oder rechtliche Strafen.
Welche Tools sind am besten für die LLM-Überwachung?
Es gibt drei Hauptkategorien: Cloud-Anbieter wie Google Cloud Vertex AI Monitoring, AWS Bedrock Monitoring und Azure AI Studio bieten integrierte Lösungen. Spezialisierte Anbieter wie Arize und WhyLabs konzentrieren sich ausschließlich auf KI-Observability und bieten tiefere Analysen. Open-Source-Tools wie Prometheus und Grafana sind flexibel, aber erfordern viel manuelle Konfiguration. Für Unternehmen in der Medizin empfehlen Experten Cloud-Lösungen mit eingebauten Compliance-Features, da Open-Source-Tools oft keine spezifischen Richtlinien für HIPAA oder GDPR enthalten.
Wie viele Testfälle brauche ich für verlässliche KPIs?
Für die meisten Unternehmensanwendungen reichen 100-500 Testfälle aus, um stabile Messwerte zu erhalten, wie Botscrew feststellt. In regulierten Branchen wie Medizin oder Finanzen sollten Sie mindestens 500 Testfälle verwenden - besser noch 1.000. Das liegt an der Notwendigkeit, seltene, aber kritische Fälle (Edge Cases) zu erfassen. Ein einziger falscher medizinischer Rat in 1.000 Antworten kann schwerwiegende Folgen haben - und muss deshalb auch in der Messung erfasst werden.
Kann ich KPIs für mehrere LLMs vergleichen?
Aktuell ist das schwierig. Nur 32 % der Unternehmen verwenden konsistente Metriken über verschiedene Modelle hinweg, wie Coralogix 2024 feststellte. Ein Modell misst Halluzinationen mit 5 %, ein anderes mit 8 %. Das macht Vergleiche unzuverlässig. Der Schlüssel ist: Definieren Sie standardisierte Definitionen für jede KPI - z. B. „Halluzination = Aussage, die nicht in den Eingabedaten oder Kontext steht und von einem menschlichen Prüfer als falsch bewertet wird“. Ohne solche Standards ist Benchmarking unmöglich.
Andreas Krokan
Dezember 17, 2025 AT 08:05Ich hab das letzte Jahr mit nem LLM im Support rumgespielt – Halluzinationen sind der absolute Horror. Mal sagt’s dem Kunden, er soll ‘Aspirin mit Zitronensaft’ nehmen, weil das ‘wissenschaftlich belegt’ ist. Nee, bro. Einfach nur: 3 KPIs einführen, Dashboard in Grafana, fertig. Kein Overengineering. Erst messen, dann heilen.
John Boulding
Dezember 19, 2025 AT 01:00Wie kann man so einen Text mit so vielen Fehlern veröffentlichen? ‘Token pro Minute’ – das ist kein KPI, das ist eine Systemmetrik. Und ‘CSAT’ ohne Definition? Wer das als ‘Business Impact’ bezeichnet, hat nie ein Audit durchgeführt. Wenn ihr nicht mal die Grundlagen der Messbarkeit versteht, warum sollte ich euch vertrauen, wenn es um medizinische Diagnosen geht?
Peter Rey
Dezember 19, 2025 AT 11:16Hallo, ich bin ein Mensch und hab neun Minuten auf eine Antwort gewartet. Kein LLM, kein Dashboard, kein KPI – nur ein Server, der sich wie ein verstopfter Abfluss verhält. Einfach: weniger Token, schnellere Antwort, mehr Zufriedenheit. Warum macht ihr das so kompliziert? 😅
Seraina Lellis
Dezember 21, 2025 AT 00:27Ich find’s echt wichtig, dass wir hier nicht nur technisch denken, sondern auch menschlich. Ich hab mal mit nem Krankenhaus zusammengearbeitet, da hat ein LLM einem Patienten gesagt, er soll ‘eine intravenöse Infusion mit Honig’ bekommen – weil ‘es in der antiken griechischen Medizin empfohlen wird’. Der Arzt hat das erst nach 47 Minuten bemerkt, weil das Dashboard nur die Latenz gemessen hat, nicht die inhaltliche Korrektheit. Also: Ja, Halluzinationsrate, aber auch menschliche Reviewer, mindestens drei pro 100 Antworten, sonst ist das nur ein schönes Spiel mit Zahlen. Und die Kosten? Die sind nicht nur für Server, sondern auch für die Leute, die die Fehler abfangen – und die werden oft vergessen.
Mischa Decurtins
Dezember 22, 2025 AT 11:51Die meisten Unternehmen messen falsche Dinge. Sie messen Token, Latenz, Serverauslastung – aber nicht, ob der Mensch hinter dem Bildschirm noch versteht, was das Modell gerade sagt. Wenn ich als Compliance Officer eine Antwort sehe, die 3 falsche Gesetze zitiert, dann interessiert mich nicht, ob die Antwort in 1,2 Sekunden kam. Ich will wissen: Warum? Wer hat den Prompt geändert? Wann? Und wer hat das nicht geprüft? Messen ist gut, aber Verantwortung ist besser. Und nein, ich hab keine Lust auf 57 Warnungen am Tag, die alle nichts bedeuten. Feinabstimmung. Nicht mehr. Nicht weniger.
Yanick Iseli
Dezember 24, 2025 AT 01:51Ein Dashboard ist keine Sammlung von Grafiken – es ist eine Entscheidungsplattform. Und das ist der Punkt, den fast alle übersehen. Wenn Sie nicht wissen, was Ihr Business-Ziel ist, dann messen Sie nichts. Sie messen nur Ihren eigenen Ehrgeiz. 90% der Kunden sollen den Vertrag abschließen? Dann messen Sie nicht die Halluzinationsrate. Messen Sie: Wie viele Kunden, die eine falsche Empfehlung bekamen, haben den Vertrag abgebrochen? Das ist die einzige Zahl, die zählt. Alles andere ist Dekoration. Und wenn Sie das nicht verstehen – dann lassen Sie das Dashboard weg. Es bringt nur mehr Stress.